|
IV. ANALYSIS OF TIME DOMAIN DATA Suppose now that one is given the time or frequency fluctuations between a pair of precision oscillators measured, for example, by one of the techniques outlined in section I, and a stability analysis is desired. Let this comparison be depicted by figure 4.1. The minimum sample time is determined by the measurement system. If the time difference or the time fluctuations are available then the frequency or the fractional frequency fluctuations may be calculated from one period of sampling to the next over the data length as indicated in figure 4.1. Suppose further there are M values of the fractional frequency yi. Now there are many ways to analyze these data. Historically, people have typically used the standard deviation equation shown in figure 4.1, s std. dev.(t ), where y is the average fractional frequency over the data set and is subtracted from each value of yi before squaring, summing and dividing by the number of values minus one, (M-1), and taking the square root to get the standard deviation. At NBS (now NIST), we studied what happens to the standard deviation when the data set may be characterized by power law spectra which are more dispersive than classical white noise frequency fluctuations. In other words, if the fluctuations are characterized by flicker noise or any other non-white-noise frequency deviations, what happens to the standard deviation for that data set? One can show that the standard deviation is a function of the number of data points in the set; it is also a function of the dead time and of the measurement system bandwidth. For example, using flicker noise frequency modulation as a model, as the number of data points increases, the standard deviation monotonically increases without limit. Some statistical measures have been developed which do not depend upon the data length and which are readily usable for characterizing the random fluctuations in precision oscillators. The IEEE has adopted a standard measure known as the "Allan variance" taken from the set of useful variances developed, and an experimental estimation of the square root of the Allan variance is shown as the bottom right equation in figure 4.1. This equation is very easy to implement experimentally as one simply need add up the squares of the differences between adjacent values of yi, divide by the number of them and by two, and take the square root. One then has the quantity which the IEEE subcommittee has recommended for specification of stability in the time domain--denoted by s y(t ).  Figure 4.1 is a simulated plot of the time fluctuations, x(t) between a pair of oscillators and of the corresponding fractional frequencies calculated from the time fluctuations each averaged over a sample time t . At the bottom are the equations for the standard deviation (left) and for the time-domain measure of frequency stability as recommended by the IEEE (right).
where the brackets "<>" denote infinite time average. In practice this is easily estimated from a finite data set as follows:
where the yi are the discrete frequency averages as illustrated in figure 4.1. One would like to know how s y(t ) varies with the sample time, t . A simple trick that one can use that is very useful, if there is no dead time, is to average the values for y1 and y2 and call that a new y1 averaged over 2t , similarly average the values for y3 and y4 and call that a new y2 averaged over 2t etc., and finally apply the same equation as before to get s y(2t ). One can repeat this process for other desired integer multiples, m, of t , and from the same data set generate values for s y(mt ) as a function of mt from which one may be able to infer a model for the process that is characteristic of this pair of oscillators. If one has dead time in the measurements adjacent pairs cannot be averaged in an unambiguous way to simply increase the sample time. One has to retake the data for each new sample time--often a very time consuming task. This is another instance where dead time can be a problem. How the classical variance (standard deviation squared) depends on the number of samples is shown in figure 4.2. Plotted is the ratio of the standard deviation squared for N samples to the standard deviation squared for 2 samples, < s 2(2,t )>, which is the same as the Allan variance, s y2(t ). One can see the dependence of this standard deviation upon the number of samples for various kinds of power law spectral densities commonly encountered as reasonable models for many important precision oscillators. Note, s y2(t ) has the same value as the classical variance for the classical noise case (white noise FM). One main point of figure 4.2 is simply to show that with the increasing data length the standard deviation of the common classical variance is not well behaved for the kinds of noise processes that are very often encountered in most of the precision oscillators of interest. 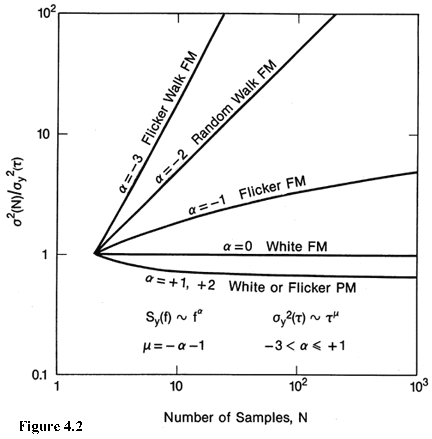 Figure 4.2: The ratio of the time average of the standard deviation squared for N samples over the time average of a two sample standard deviation squared as a function of the number of samples, N. The ratio is plotted for various power law spectral densities that commonly occur in precision oscillators. The figure illustrates one reason why the standard deviation is not a convenient measure of frequency stability; i.e., it may be very important to specify how many data points are in a data set if you use the standard deviation. One may combine eq (1.4) and eq (4.1), which yields an equation for s y(t ) in terms of the time difference or time deviation measurements. which for N discrete time readings may be estimated as, ![sigma y(m tau 0)about =[1/(2(N-2)tau squared) * sum from i=1 to n-2 (-x sub(i+2) + 2x sub(i+1)-x sub i)squared] to the .5](Properties_images/Image28.gif) where the i denotes the number of the reading in the set of N and the nominal spacing between readings is t . If there is no dead time in the data and the original data were taken with a sample time t 0, a set of xi's can be obtained by integrating the yi's
Once we have the xi's, we can pick t in eq (4.4) to be any integer multiple of t 0, i.e., t = mt 0:
Equation (4.6) has some interesting consequences because of the efficient data usage in terms of the confidence of the estimate as will be explained in the next section. EXAMPLE : Find the two-sample (Allan) variance, s y2(t ), of the following sequence of fractional frequency fluctuation values yk, each value averaged over one second.
Since each average of the fractional frequency fluctuation values is for one second, then the first variance calculation will be at t = 1s. We are given M = 8 (eight values); therefore, the number of pairs in sequence is M-1 = 7. We have:
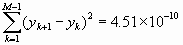 Therefore, the Allan variance is 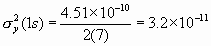 and the Allan deviation is s y(t ) = [s 2y(1s)]2 = [3.2 x 10-11]2 = 5.6 x 10-6 Using the same data, one can calculate the Allan variance for t = 2s by averaging pairs of adjacent values and using these new averages as data values for the same procedure as above. For three second averages (t = 3s) take adjacent threesomes and find their averages and proceed in a similar manner. More data must be acquired for longer averaging times. One sees that with large numbers of data values, it is helpful to use a computer or programmable calculator. The confidence of the estimate on s y(t ) improves nominally as the square root of the number of data values used. In this example, M=8 and the number of first differences is 7, so the confidence can be expressed as being no better than 1/ Ö7 x 100% = 38%. This is a 1-sigma uncertainty (68% confidence interval) in the estimate for the t = 1s average. The next section shows methods of computing and improving the confidence interval.
Main Page |
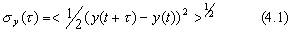
![sigma y (t)=[1/(2(M-1))sum from i=1 to M-1(y sub (i+1)-y sub (i))squared] to the .5](Properties_images/Image25.gif)
![sigma y(m tau 0) =[1/(2(N-2m)tau 0 squared) * sum from i=1 to n-2m (-x sub(i+2m) + 2x sub(i+m)-x sub i)squared] to the .5](Properties_images/Image30.gif)